

 Thomas Eiszler
Thomas Eiszler
OpenScout is an edge-native application designed for automated situational awareness. The idea behind OpenScout was to build a pipeline that would support automated object detection and facial recognition. This kind of situational awareness is crucial in domains such as disaster recovery and military operations where connection over the WAN to the cloud may be disrupted or temporarily disconnected.
Based upon the Gabriel platform, OpenScout performs object detection and facial recognition on the image frames sent by Android clients in the field. The information extracted from these images is then propagated into an ELK ( elasticsearch-logstash-kibana ) stack where further analysis and visualization can occur. The client is also returned this information for debugging purposes. Images with the bounding boxes of the objects and faces that were detected can optionally be stored on the server for further evaluation.
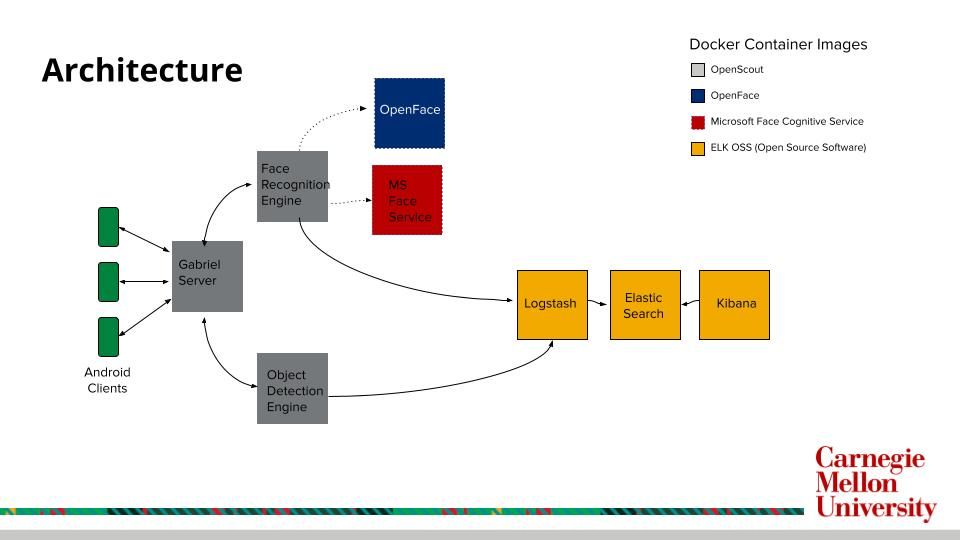
Just like other Gabriel applications, OpenScout clients connect to the core Gabriel container. The Gabriel server passes the image frames to both the object detection and face recognition engines. Currently we support two different methods for face recognition: OpenFace which was developed at CMU and is opensource; and Microsoft’s Face Cognitive service. The results from both the engines are then pushed into an ELK stack where other users can query, analyze, and visualize the data captured.
The object detection engine is based on Tensorflow and the included DNN is SSD Resnet 50 based upon the COCO dataset. Though OpenScout is packaged with SSD-Resnet 50, any Tensorflow model can be used. This includes any other DNN from the Tensorflow model zoo or a custom trained model.
For face recognition, we have included a default training set which includes three celebrities: Dwayne Johnson, Saorise Ronan, and Hugh Jackman. New faces can be trained in two ways: either ad-hoc from the Android client, or by manually adding training images to the face engine docker container before runtime.
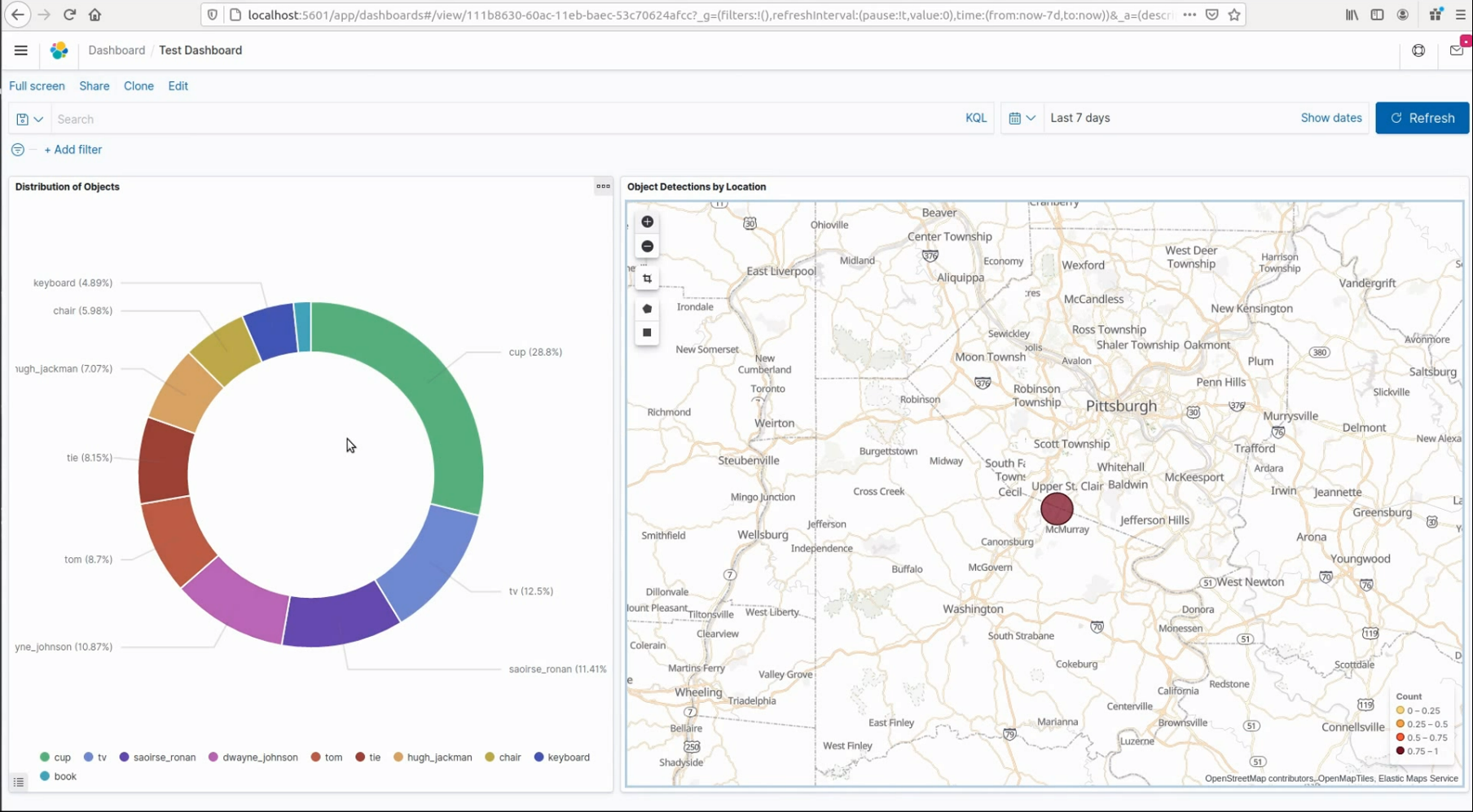
After being processed by the cognitive engines, data is then pushed into ELK, allowing for visualizations like the one shown above. On the left is a pie chart that shows the distribution of the types of objects that have been detected. The map on the right shows the number of detections by location, leveraging the GPS coordinates sent by the device with each frame.
We envision additional cognitive engines in the future that can run in parallel to the object detection and face recognition algorithms. One can imagine having an image classifier that attempts to classify the national origin of military equipment or garb, based upon colors, flags, or other insignia. Or perhaps running OCR on images to automatically extract textual information observed in the field.
A video demonstration of OpenScout can be seen below, where we recognize celebrity faces, detect some household objects, and train the face recognition engine on the fly to recognize a new face.
OpenScout is open-source (Apache License 2.0). The source code is available on Github while the backend Docker image can be pulled from Docker Hub and the Android client can be downloaded from the Google PlayStore .